Sharding Introduction
Sharding是用於跨多個機器儲存時的一種技術。MongoDB使用Sharding支援部署大量資料集,及高存取流量操作。
Purpose of Sharding
應用程式在處理大資料集跟高存取量時,對單一Service上的資料庫系統,是一個很高的挑戰。
高查詢率會消耗CPU資源,大資料集所需容量,超過單一機器所能負荷。執行時的記憶體使用量,超過單一機器所能提供,進而挑戰機器的disk I/O。為了解決上述問題,資料庫系統有2個基本方法,重直擴展【 vertical scaling】和【sharding】.
重直擴展(Vertical scaling):增加CPU及增加Storage的容量,但這些都是有極限的。高效率的系統有大量的cup及 高記憶體,比小系統的成本還高。另外雲端系統供應商也許只提供使用者,小的instance,依照這個結論,重直擴展是有它最大的極限。
碎片化(Sharding):也可稱為水平擴展,分割的資料集及分散的資料,被存在數個不同的Service上或shard上,每一個碎片(shard)都是一個獨立的資料庫跟集合體,數個shards可以組成一個邏輯資料庫(logical database)。

- 碎片化(Sharding)可以減少對每一個shard的操作,以新增為例新增資料應用程式只需要,存取某個記錄的shard。
- 碎片化(Sharding)可以減少每個Server所需的stroage。以1TB的資料為例,可以存在4個shard每個shard只需用256GB,如果有40個shard每個只需要25GB.
Sharding in MongoDB
MongoDB的sharding是透過shared Cluster的configuration來實作。

碎片組(Shards):用來儲存資料。提供高可用度及一致性的資料。在正式環境中,Sharded Cluster裡的每一個shard(碎片),都是一個複製資料集。
Query Routers:也可稱為 mongos instances,透過client Application及直接操作去佔用一個或多個碎片(Shard)。查詢程序或操作特定shards(碎片組)進而回傳結果會client。一個shared Cluster會包含多個Query Router去分開執行一個Client所發出的Request。1個client可以發出多個request給1個query Router。多數的shared clusters會有多有個query router.
Config servers:存放cluster的metadata。包括cluster中的資料集與shards的對照,Query Router用這些matadata去操作做特定的shards。正式的shared cluster會有3個config Server。
Data Partitioning
MongoDB是以collection層級,做分散資料或碎化(shards)。利用shard key來達到碎化(shard)一個collection中的資料。
Shard Keys
碎化(shard)一個collection,需要去找出shard key。Shard key會是index欄位或是一個複合式index而這個複合index存在每一個document。MongoDb劃分shard key值並將值寫入數個chunk而且分在數個不同的Shards。劃分shard key值,MongoDb使用range based partitioning or hash based partitioning其中一種方式。
Range Based Sharding
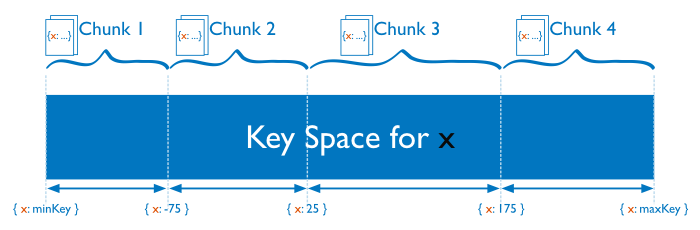
Hash Based Sharding

Splitting

Balancing
balancer這支background service會去管理chkunk的搬移。當碎化(Shard)的collection在cluster分配不平均時,blanacer會從最多chunk的shard搬移chunk至最少的shard,直到整個collect平均為止。

Adding and Removing Shards from the Cluster
新增1個shard到cluster,因為shard沒有chunk,導致shard分配不平均。MongoDB會開始馬上搬資料到新的shard,這個動作會花一些時間,直到cluster達到平均的狀態。
刪除1個shard會先將其中的所有chunk搬到其它的shard,直到全部搬完及更新metadata後,才可以移除shard。
沒有留言:
張貼留言